About FE108
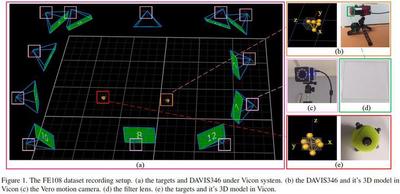
The FE108 dataset is captured by a DAVIS346 eventbased camera, which equips a 346x260 pixels dynamic vision sensor (DVS) and an active pixel sensor (APS). It can simultaneously provide events and aligned grayscale images of a scene. The ground truth bounding boxes of a moving target are provided by the Vicon motion capture system, which captures motion with a high sampling rate (up to 330Hz) and sub-millimeter precision. During the capturing process, we fix APS’s frame rate to 20/40 FPS and Vicon’s sampling rate to 240Hz, which are also the annotation frequency of the captured APS frame and accumulated events, respectively. FE108 is featured in
> High-quality label. The Vicon system can provide the 3D position in sub-millimeter precision.
> Diversity in target. 21 classes (animal, vehicle, and daily goods).
> Diversity of event rate. Avg event rate in (0, 3800] Ev/ms.
> Real world challenges. Low light, high dynamic range, fast motion, motion blur and so on.
Download
Application for Access for Non-Commercial Use
How to use FE108

run stack_event.py to generate event frames, we aggregate the events captured between two adjacent frames into an 3-bin voxel grid to discretize the time dimension. To load the aedat4 file, you should install the required toolkit dv-gui. More details about dv-gui can be found here. You can download .txt and .py from here.
python stack_event.py 0 108
Preview of Sample Videos
Expand Dataset
We are expanding our FE108 by collecting more challenging sequences (> 50), especially with more realistic scenes. We expect to complete the collection and upload it here by the end of September.
News! we have collected additional 33 sequences, which contains more challenging scenes for event-based data, such as similar object, severe camera motion, and strobe light. We also open our 240hz annotation, named FE240hz, which contains 143,181 frame images.
Reference
Please consider citing FE108 if it is helpful for you :)
Object Tracking by Jointly Exploiting Frame and Event Domain
Jiqing Zhang, Xin Yang, Yingkai Fu, Xiaopeng Wei, Baocai Yin, Bo Dong
IEEE International Conference on Computer Vision (ICCV), July, 2021