Efficient Vision Transformer with Token Sparsification for Event-Based Object Tracking (IJCV 2026)
Abstract
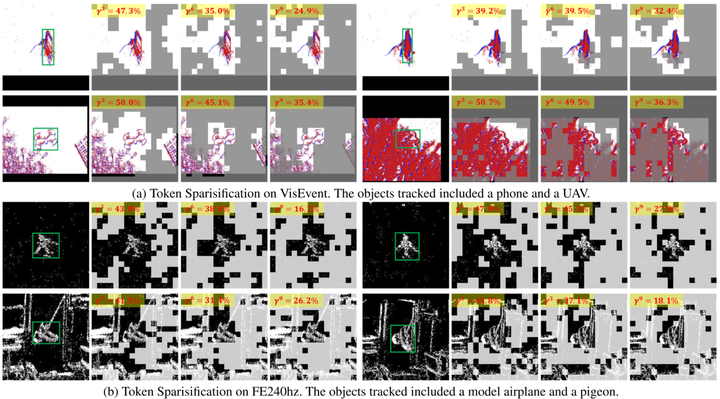
The Vision Transformer has gained popularity as a neural network architecture for event-based vision tasks. However, its use on resource-constrained devices is limited due to high computational and memory costs. This paper presents an Efficient Vision Transformer, a novel backbone for object tracking with event cameras. Specifically, we propose two adaptive token sparsification strategies based on the inherent characteristics of event data and tracking tasks, thereby reducing the computation while maintaining comparable performance. Firstly, since events are spatially sparse at pixel locations, we adaptively predict the sparsification ratio based on statistical entropy analysis and subsequently remove search tokens exhibiting dissimilarity to template tokens. Besides, we further eliminate redundant tokens by estimating the importance score of each token given the tracking targets. By hierarchically pruning more than 60% of the input tokens of vanilla Vision Transformer (ViT), our method significantly reduces MAC operations by approximately 25%, while the tracking accuracy drops by no more than 0.5%. Extensive experiments on various event-based tracking datasets demonstrate that our proposed approach outperforms existing state-of-the-art methods in both tracking accuracy and speed.